In Translation Quality Blog I have added a couple of new posts with links to articles that deal with translation and localization quality control and measurement:
Standards and Models
and
Translation Quality Measurement Approaches

Tuesday, May 23, 2006
Monday, May 22, 2006
OCR for Free
A fairly frequent question in translators' fora is "how do I convert a (jpg, or tif, or pdf) file", so that I can work on it in MS Word.
For pdf files, the solution is sometime as simple as opening the file in Acrobat, and saving it as a MS Word or rtf file. But often this approach doesn't work (for example because the pdf was created from a graphic file, and not a text one).
For graphic files such as jpg or tif files, of course, "saving as" a Word file is not an option.
So often the solution offered is to use some OCR package. Professional ones may give good results (if the quality of the original is good), but they cost money, and the free OCR applications that come with a scanner are usually very disappointing: they may not recognize accented letters, or fail to properly keep the layout of the page (after all, they are given away so as to induce customers to upgrade to the full version).
A better alternative, at least for users of the latest versions of MS Office, is to take advantage of Microsoft Office Document Imaging: it is better than most other "free" OCR applications, may be upgraded (if necessary) to one of the leading "pro" OCR packages, and, on its own, already recognizes things such as tables and accented characters.
For pdf files, the solution is sometime as simple as opening the file in Acrobat, and saving it as a MS Word or rtf file. But often this approach doesn't work (for example because the pdf was created from a graphic file, and not a text one).
For graphic files such as jpg or tif files, of course, "saving as" a Word file is not an option.
So often the solution offered is to use some OCR package. Professional ones may give good results (if the quality of the original is good), but they cost money, and the free OCR applications that come with a scanner are usually very disappointing: they may not recognize accented letters, or fail to properly keep the layout of the page (after all, they are given away so as to induce customers to upgrade to the full version).
A better alternative, at least for users of the latest versions of MS Office, is to take advantage of Microsoft Office Document Imaging: it is better than most other "free" OCR applications, may be upgraded (if necessary) to one of the leading "pro" OCR packages, and, on its own, already recognizes things such as tables and accented characters.
Sunday, May 21, 2006
Visual Thesaurus: a Gorgeous-Looking Tool
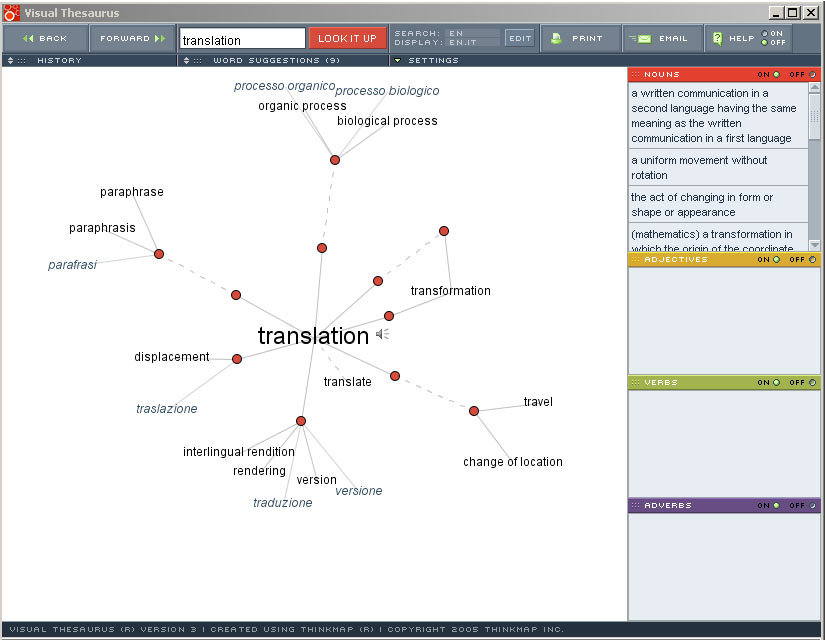 I had seen a beta version of the Visual Thesaurus some time ago.
I had seen a beta version of the Visual Thesaurus some time ago.Then when it was finally released I kept on coming back to their web site, like a child returning to the window of a toy store, but never purchased it (what's the use... I've already got several thesauri on paper plus more in my word processor and other applications).
Still, it kept tantalizing me: I never deleted the link from my favorites, and from time to time kept coming back to give it a new look.
Finally, a few days ago, I decided to try a monthly subscription (the tool comes either as a standalone installable application, or as a web subscription).
I think that I am going to upgrade both to a full yearly subscription and to the standalone version (just in case the web is down).
The web version includes a beta version of a multilingual thesaurus (click on screenshot above to get a bigger image) . Though the multilingual content is a bit patchy at the moment, it promises to become a great tool for translators. It already is a wonderful tool for anybody who writes in English, or who is in love with words.
Highly recommended.
Friday, May 12, 2006
Interesting Article on Quality Certification for LSPs
Common Sense Advisory has published an interesting article on quality certification programs for LSPs (Language Service Providers).
Among the interesting things mentioned in the article there is the fact that only 10% of LSPs have ISO 9000 certification.
Among the interesting things mentioned in the article there is the fact that only 10% of LSPs have ISO 9000 certification.
MemoQ, a New Translation Tool, Launched
Kilgray has just launched MemoQ, a new translation memory tool. According to Kilgray's web site,
From the screen shots provided on Kilgray's web site, it looks more like DejaVu then either Trados or Wordfast. Of course, before forming a definite impression, it would be necessary to try the program on a real project.
One version of the program is free, others have prices that appear lower than comparable offerings from SDL/Trados.
(Hat tip to Christof)
MemoQ is the first integrated translation environment, developed in Central Europe, which surpasses its competitors with its performance, savvy user interface and integration capability.Among the features that look interesting is support for Trados .ttx files, as well as support for TMX 1.1 and 1.4 memories.
From the screen shots provided on Kilgray's web site, it looks more like DejaVu then either Trados or Wordfast. Of course, before forming a definite impression, it would be necessary to try the program on a real project.
One version of the program is free, others have prices that appear lower than comparable offerings from SDL/Trados.
(Hat tip to Christof)
Thursday, May 11, 2006
Courses on Translation and Interpretation at the University of Denver
The University of Denver has recently started to offer courses on translation and interpretation, and plans to expand its curriculum in this field.
Registration for the clases given this summer (Introduction to Translation Software and Interpreter Training for K-12 Professionals) is already open.
You can dowload a brief pdf prospectus here, or you can call Holly Dunn at 303.871.3935 or e-mail her at hdunn@du.edu.
Registration for the clases given this summer (Introduction to Translation Software and Interpreter Training for K-12 Professionals) is already open.
You can dowload a brief pdf prospectus here, or you can call Holly Dunn at 303.871.3935 or e-mail her at hdunn@du.edu.
Tuesday, May 09, 2006
"Italians" - Letter About Translation Bloopers
Beppe Severgnini's Italians today published a letter by Mauro Luglio ("Le traduzioni dei manuali d’istruzione") about translation errors, especially in instruction manuals.
Among the bloopers quoted: "Attenzione! Noi vogliamo farvi godere!" (on the user's manual of an electric shaver)
"Attenzione! L'orologio non deve mai essere messo sulla testa!" (from the instructions of a cuckoo clock)
Among the bloopers quoted: "Attenzione! Noi vogliamo farvi godere!" (on the user's manual of an electric shaver)
"Attenzione! L'orologio non deve mai essere messo sulla testa!" (from the instructions of a cuckoo clock)
Monday, May 08, 2006
Advice to Beginning Translators (4) - Translation Tests
Often when we contact a translation company (and sometimes when a translation company contacts us), we are asked to do a translation test, or sample translation, as a preliminary to possible collaboration with them.
Many translators object to doing translation tests for free, on various grounds, from the fact that other professionals do not do free tests (which is not exactly true, as many lawyers and other professionals do provide free consultations, after which you can decide whether to retain them or not), to the fact that translation tests are allegedly used by unscrupulous agencies to stitch together the translation of an entire book done for free (which I have always thought a translator's urban legend, as this is something people always hear but never actually see first hand, and also because any agency that would attempt a stunt like that would soon be out of business, as the resulting quality of such a patchwork would certainly be abysmal).
Another objection is that translation tests mean little, and that translation companies should rely instead on the work experience, education, or other indicators of a translator's worth, which is a valid objection, but would not help one gain work from an agency who has decided to use translation tests in their screening process: normally, if you don't do the test, you also don't work for them.
In my opinion, the best objection to doing free translation tests is that one has no time for that: if you already have enough work, doing a translation test for free is probably not the best investment of your time.
If one decides to do the translation tests, there are several things to consider:
If you are interested in the previous posts in this series, you can find them here (Advice to Beginning Translators - 1 Résumés), here (Advice to beginning translators - 2 Seindg Out Your Résumé), and here (Advice to beginning Translators - 3 Contacting Prospects)
Many translators object to doing translation tests for free, on various grounds, from the fact that other professionals do not do free tests (which is not exactly true, as many lawyers and other professionals do provide free consultations, after which you can decide whether to retain them or not), to the fact that translation tests are allegedly used by unscrupulous agencies to stitch together the translation of an entire book done for free (which I have always thought a translator's urban legend, as this is something people always hear but never actually see first hand, and also because any agency that would attempt a stunt like that would soon be out of business, as the resulting quality of such a patchwork would certainly be abysmal).
Another objection is that translation tests mean little, and that translation companies should rely instead on the work experience, education, or other indicators of a translator's worth, which is a valid objection, but would not help one gain work from an agency who has decided to use translation tests in their screening process: normally, if you don't do the test, you also don't work for them.
In my opinion, the best objection to doing free translation tests is that one has no time for that: if you already have enough work, doing a translation test for free is probably not the best investment of your time.
If one decides to do the translation tests, there are several things to consider:
- The test should be of an acceptable length (normally no more than 500 words or so).
- Read carefully, and follow any instructions given together with the test: when I worked as a manager in the translation department of a major business software company, we used translation tests as a part of our screening process. We never asked to translate more than 250 to 350 words, but we normally sent out tests in which the words to translated were clearly marked within longer texts. Failure to follow the instructions (by, for example translating more than we had asked) was a serious mark against our candidates, since it was indicative that these translators would not be good at following instructions in a real work environment, either.
- If you accept to do the test, do your best, and treat it as a real work assignment: put your best foot forward.
- Do not leave alternate translations: you would not do that in a real work assignment, and you should not do in a test (any alternate translations left in a test would normally be marked as an error).
- Do not add translator's notes, unless specifically requested to do so in the instructions: I've seen many apparently acceptable tests fail because the translation notes made clear that the translator had not, in fact, understood the meaning of some sentence or term.
- Do not have someone else translate the test for you: I've seen it done, and more often than not cheats are quickly found out, if not during the test evaluation, eventually with the first work assignment.
Finally... - Do not use Babelfish to do the test (happened: we once received a test which looked really terrible. We began to joke that Babelfish probably would not do it worse, so we run the test through Babelfish, just to see how much worse a free MT program would do it... turned out it did it exactly the same, as the would be translator had used it to do the test).
If you are interested in the previous posts in this series, you can find them here (Advice to Beginning Translators - 1 Résumés), here (Advice to beginning translators - 2 Seindg Out Your Résumé), and here (Advice to beginning Translators - 3 Contacting Prospects)
TagEditor Sundry Annoyances
I don't mind working in Trados' TagEditor - at least it is much better than translating Power Point files in the dread T-Window application, but TagEditor sure has more than its fair share of annoying quirks:
- Since this is basically a no-frill text editor, why does it attempt to display fonts in a half-assed WYSIWYG way? (especially since it does it in such a buggy way: text that changes sizes on screen for no understandable reason, or displays in bold and/or italic when it is neither). Admittedly, these display defects do not affect the translation, but why have them at all, since the preview function is just a click away (and works reasonably well)?
- Why do source string, translated string, etc. all are displayed in the same color, instead of using the colors one sets in Workbench?
- Trying to use the MS Word spell-checker still doesn't always work, and
- If you use the supplied spell checker, the Check Spelling window comes up, by default, with the focus on the "Not in dictionary" field, instead of the "Change to" field, as would be logical.
- Why such a puny internal search function: you can only specify a search string, a replacement string, whether to match whole words only or not, whether to match case or not, and (for the search function only) whether to search up or down: no regular expressions, not even the scaled down version one can find in MS Word's wildcard searches... and this when such functionality is easily available in text editors that sell for just a few bucks (such as Text Pad).
Thursday, May 04, 2006
Googling Within a Site
One thing I'm frequently asked to do is to make sure the translation I'm doing or editing is consistent with the fairly large corpus of literature in the customer's web site.
Some of the consistency checking I can take care of by checking previous translation memories, or glossaries (if they exist), and some using the search functions within the site itself.
However, using the search box provided within a site is often not enough. A technique that I find very useful in these cases is to google within the site.
Say for example that I need to see within the Italian portion of my customer whether in the past they have used more often "implementazione dell'applicazione" or "deployment dell'applicazione".
If my customer's Italian web site is, for example
Some of the consistency checking I can take care of by checking previous translation memories, or glossaries (if they exist), and some using the search functions within the site itself.
However, using the search box provided within a site is often not enough. A technique that I find very useful in these cases is to google within the site.
Say for example that I need to see within the Italian portion of my customer whether in the past they have used more often "implementazione dell'applicazione" or "deployment dell'applicazione".
If my customer's Italian web site is, for example
http://www.xyz.com/IT, I just need to enter in the google search box"deployment dell'applicazione" site:http://www.xyz.com/IT"implementazione dell'applicazione" site:http://www.xyz.com/ITWednesday, May 03, 2006
New Version of Translator's Tool Box
The Translator's Tool Box is an e-book aimed at professional translators. It contains a wealth of information about software useful to translators: from useful information on how to use various features of the operating system and of Office application to a discussion of CAT tools and to information on more specialized "little" utilities such as Search & Replace or Clipmate, and much more.
We have just received the fourth edition, which adds information on how to translate complex file formats (such as XML).
Highly recommended.
We have just received the fourth edition, which adds information on how to translate complex file formats (such as XML).
Highly recommended.
Tuesday, May 02, 2006
Another Useful Wildcard Search
(c) Riccardo Schiaffino 2006
When working with Trados and MS Word, I often take advantage of the fairly powerful wildcard search options of Word - which are really a scaled-down and non-standard version of regular expressions. In a previous article from last year (How to use wildcard and format searches in MSWord to make sure all your numbers are formatted correctly), I showed how wildcard searches could be used to make sure that numbers in a translation are formatted properly according to the target language rules. In this post we are going to see another way wildcard searches may be of use to translators when working with Trados.One of the tasks I regularly use MS Word wildcard searches for is to make sure that index entries in Framemaker's .mif files that I'm translating as rtf (after conversion with S-tagger) are formatted correctly: according to the style guide I have to follow, index entries in Italian should normally start with a lower-case letter (unless they are the name of some program).
Problem is, index entries are, by their very nature, standalone segments (which normally start with an upper case letter), and also segments that are very likely to be used elsewhere: "Program Installation" may be a section title, and, at the same time, an index entry in English. In Italian, however, I need to have "Installazione programma" for the title, and "installazione programma" for the corresponding index entry.
Working in Trados with a large memory, with segments that come from other translators and other projects, it is often easy to have the various index entries already translated from perfect matches, and, likely with a mismatch of upper and lower cases.
I thought that the best solution would be some search string able to find only index entries that, in Italian, begin with an upper case letter. At that point I could manually make them lower case by pressing F3, or leave them as is when they actually needed to be upper case.
The first part of the search string was going to be easier, as all index entries begin with either the <il> or <ie> markup.
So I knew that my search string needed to begin with\<i[el]\>
This means:
\<- Find all the strings that begin with the "open markup" sign (the open angle bracket "<"; the backslash character "\" is used to indicate that the character that follows needs to be taken literally, and is necessary because the angle bracket characters otherwise have special meaning within wildcard searches.i- Followed by an "i"[el]- Followed by either an "e" or an "l" (the square brackets surrounding "el" group the alternate valid characters.<ie>and<il>are two markups that precede index entries in .mif files)\>- Followed by the "close "markup" sign.
Now we need to search beyond the entire English source segment, whatever it contains, until we reach the first letter of the Italian one. In order to do this, we can take advantage of the Trados source segment delimiters "{0>" and "<}0{>".
Therefore the search strings needs to continue with
\{0\>[A-Za-z,;:\-\*\!\?\(\)\\\/"'=.£%&+\@#°_ 0-9]{1,255}\<\}[0-9]{1,3}\{\>
This looks quite complicated and unreadable (fine-tuning this part of the search string took quite a long time, and it probably is still not perfect). It means:
\{0\>- Trados markup to indicate the begin of the source language string (the first backslash character indicates that the open bracket "{" needs to be taken literally, since on its own it has other uses within the wildcard search, as we shall see presently)[A-Za-z,;:\-\*\!\?\(\)\\\/"'=.£%&+\@#°_ 0-9]- All the characters that could be contained within the source language string. Again, backslashes precede characters that otherwise would have special meaning within the wildcard search. The square brackets are used again to group all the possible characters.
Now, let's explain a little further these "all possible characters":A-Za-z- All alphabetical characters,;:- Comma, semi-colon and colon\-\*\!\?\(\)- Various punctuation and symbol marks (-*!?()each preceded by the backslash to indicate it has to be taken literally)\\- The backslash "\" symbol itself (when it is doubled thus, the first backslash indicates that the second one is to be taken literally)\/- The forward slash "/""'=.£%&+\@#°_- Various other punctuation and other symbols (double-quote, single-quote, equal sign, full stop, etc., up to the underscore sign "_"0-9- All numerical characters
{1,255}- Here is one of the special uses of the brackets within wildcard searches: they are used to indicate how many characters (any combinations of the previously listed ones from "A-Z" through "0-9" can be contained in the previous part of the search. "1,255" means "from a single character through the maximum allowed (which unfortunately is only 255).\<\}[0-9]{1,3}\{\>- Trados markup to indicate the end of the source language string and the beginning of the target language.
\<\}- Beginning of the markup used by Trados between SL and TL
[0-9]- Indicates that the markup may contain here any number
{1,3}- Indicates that the number contained in the markup may be between 1 and three digits (in fact, between 0 and 100)
\{\>- End of the markup used by Trados between SL and TL
Finally we need to indicate that we are looking only for those index entries in which the target language strings begins with an upper case:
[A-Z] - That is "All upper case alphabetical characters between 'A' and 'Z'"
Our complete search string will therefore be:
\<i[el]\>\{0\>[A-Za-z,;:\-\*\!\?\(\)\\\/"'=.£%&+\@#°_ 0-9]{1,255}\<\}[0-9]{1,3}\{\>[A-Z]
This needs to be typed exactly as is in Word's search dialog.
I keep a text file with all the wildcard search strings I know I'm going to use in the future, and when I need them I copy from the text file to Word's search dialog, and I suggest doing the same if you start using wildcard searches.
Wildcard searches are probably not for everybody: they look cryptic, may be very complicated, and usually take a fair amount of time to get right. On the other hand, as we have seen, they may help solving problems that may be difficult to solve any other way.
If you are interested in more information about wildcard searches, my previous post) contained some references. In addition to those, I suggest a book on regular expression that has been published recently, and that contains an entire chapter devoted to wildcard searches in MS Word: Andrew Watt's Beginning Regular Expression, published by Wrox.
Monday, May 01, 2006
Forecast Growth of the Translation Market
The New York Times published yesterday an article (Speaking in (Many) Tongues Can Be Profitable), on the growing importance of translation and interpreting, with the federal Bureau of Labor Statistics forecasting a 20% growth in the number of translators and interpreters between 2004 and 2014.
Subscribe to:
Posts (Atom)